Kubetos Thesis
1. Введение
В этой части надо описать предметную область, задачу из которой вы будете решать, объяснить её актуальность (почему надо что-то делать сейчас?). Здесь же стоит ввести определения понятий, которые вам понадобятся в постановке задачи.
На сегодняшний день большое количество вычислений осуществляется в парадигме облачных вычислений. Облачные вычисления - это предоставление вычислительных услуг таких как серверы, хранилища, базы данных, сети, программное обеспечение и многое другое, что позволяет пользователям получать доступ к этим ресурсам по требованию, по мере необходимости. Эти услуги обычно предоставляются сторонними поставщиками, которые управляют базовой инфраструктурой и обеспечивают ее доступность, безопасность и масштабируемость.
В облачных вычислениях существует три основные модели услуг, предлагаемых провайдерами: IaaS (инфраструктура как услуга), PaaS (платформа как услуга) и SaaS (программное обеспечение как услуга).
- IaaS - это самая базовая модель обслуживания, при которой поставщики облачных услуг предлагают виртуализированные ресурсы инфраструктуры, такие как виртуальные машины, хранилища и сети, которые клиенты могут использовать для создания собственных приложений и услуг.
- PaaS - это модель услуг более высокого уровня, которая предоставляет клиентам платформу для разработки, тестирования и развертывания приложений без необходимости заботиться об управлении служебной инфраструктурой.
- SaaS - это модель услуг высокого уровня, при которой поставщики облачных услуг предлагают полностью управляемые программные приложения, к которым клиенты могут получить доступ и использовать их через Интернет. Приложения SaaS обычно разрабатываются для конкретных случаев использования, таких как электронная почта, облачные хранилища данных (Yandex Disk, Google Drive, …) или инфраструктура для разработки проектов (Gitlab, Figma, …), и доступ к ним осуществляется через веб-браузеры или специализированные клиенты.
Научное сообщество также выделяет такую модель, как Everything as a Service (XaaS) [ссылка]. Это буквально означает: всё, как услуга. Такой термин применяется тогда, когда предоставляемые услуги невозможно разделить на более простые составляющие.
Современные программные системы вышли за границы одного вычислительного узла, распределены по нескольким компьютерам и взаимодействуют через сеть. Настройка и поддержка таких систем является сложной задачей, которая требует от разработчиков и системных администраторов не только знаний в области программирования и архитектуры ПО, но и понимания особенностей работы сетей, протоколов передачи данных, безопасности и других аспектов. Кроме того, необходимо уметь эффективно масштабировать системы, обеспечивать их отказоустойчивость и производительность, а также быстро реагировать на возможные проблемы и сбои в работе.
Одним из основных подходов к решению проблемы поддержки сложных систем является «инфраструктура как код» (IaC), которая предполагает использование кода и средств автоматизации для управления и предоставления ресурсов инфраструктуры последовательным, повторяемым и масштабируемым способом. В качестве ресурсов могут служить виртуальные машины, сети и хранилища. Такой подход позволяет организациям относиться к своей инфраструктуре как к ПО, со всеми вытекающими отсюда преимуществами, такими как контроль версий, тестирование и автоматизация развертывания.
Одним из подходов к реализации IaC является оркестрация. Оркестрация — это тип композиции, где один конкретный элемент используется композицией для управления другими элементами [ISO/IEC TS 23167, 3.12]. Оркестрация позволяет автоматически размещать, координировать и управлять сложными компьютерными системами и службами. Существует множество инструментов и фреймворков автоматизации, используемых для решения задачи оркестрации, каждый из которых имеет свой собственный язык и подход. Среди них: Kubernetes, Docker Swarm, Terraform, Ansible, Puppet, Chef и многие другие.
Отдельно стоит выделить языки высокоуровневого моделирования облачных приложений [@bergmayr_systematic_2019]: TOSCA, OpenStack Heat, Amazon CloudFormation. Недавнее исследование [@bhattacharjee_model-driven_2018], в котором было задействовано порядка 50 студентов, на примере использования CloudCAMP показало, что такие высокоуровневые модели сильно упрощают работу с инфраструктурой, не теряя при этом гибкости. Исследуемый фреймворк был основан на стандарте TOSCA, который является наиболее популярным среди существующих языков моделирования облачных приложений.
Topology and Orchestration Specification for Cloud Applications (TOSCA) [@noauthor_oasis_nodate] - это открытый стандарт для описания топологии, воспроизводимого развёртывания облачных приложений и сервисов по требованию и управления их жизненным циклом. TOSCA предоставляет стандартизированный способ моделирования сложных, многоуровневых приложений и сервисов, включая их компоненты, зависимости и взаимосвязи.
С помощью TOSCA определения облачных приложений могут быть представлены в стандартном, переносимом и многократно используемом формате, предназначенном для облегчения управления облачными приложениями и инфраструктурой. TOSCA разработан для поддержки различных сценариев развертывания облачных сред, включая публичные, частные и гибридные облачные среды, и предоставляет комплексную и гибкую модель для определения требований, возможностей и взаимосвязей облачных компонентов. TOSCA - это открытый стандарт, поддерживаемый OASIS, международной организацией по стандартизации, что обеспечивает его широкое внедрение и долгосрочную жизнеспособность.
Единицей представления облачных приложений в стандарте TOSCA является шаблон, представляющий собой YAML файл. В шаблоне описываются узлы (nodes), являющиеся единицами развёртывания, и отношения между ними (relationships). Одним из основных преимуществ TOSCA является высокий уровень абстракции языка описания топологий, что позволяет применять его в широком спектре задач и встраивать слой TOSCA между конечным пользователем и более низкоуровневыми инструментами IaC. Это даёт возможность упростить как задачи проектирования и тестирования разрабатываемых моделей сервисов, так и последующие задачи администрирования, обновления, миграции развёрнутой инфраструктуры. Поэтому в больших, сложных средах с большим количеством приложений и сервисов встраивание TOSCA может сократить операционные расходы, в то время как для более простых сред или конкретных случаев использования Ansible может быть более подходящим решением.
Важной частью стандарта TOSCA является механизм Substitution Mapping, позволяющий динамически заменять один узел набором других в моделировании инфраструктуры, осуществлять композицию шаблонов, чтобы улучшить переносимость между разными облачными провайдерами. Он полезен в тех случаях, когда необходимо поддерживать одну и ту же архитектуру приложения, используя различные конфигурации. Различие конфигураций может быть обусловлено различием используемых облачных окружений или выбором реализаций определённых протоколов. Это упрощает проектирование, развёртывание и управление инфраструктурой в мультиоблачных средах. Этот же механизм позволяет создать систему оркестрации, которая может работать без предположений о внешнем мире, быть доменно-независимой. Расширение будет производиться только через написание новых TOSCA шаблонов. Отсюда следует возможность создания системы, не зависящей от облачного провайдера, развёртываемого сервиса и даже, в некоторой степени, инструмента развёртывания.
На данный момент, в ИСП РАН разрабатывается две системы оркестрации: Clouni [@noauthor_clouni_2022] и Michman [@noauthor_isprasmichman_2023]. Система Clouni разработана для унификации именования одних и тех же сущностей у разных провайдеров облачных услуг через стандарт TOSCA, поэтому работает в первую очередь с уровнем IaaS и реализует собственный механизм специализации шаблона под конкретного облачного провайдера, не являющийся частью TOSCA. Также Clouni не обладает набором готовых сервисов, которые можно развернуть с помощью этой системы. Michman же не поддерживает стандарт TOSCA, но поставляется с богатой коллекцией сервисов, позволяя разворачивать большое количество PaaS и SaaS платформ, настраивая их через REST API Michman. Далее в обзоре особенности данных систем будут описаны более детально.
Актуальной задачей является объединение преимуществ оркестраторов Michman и Clouni в новой системе оркестрации, основанной на TOSCA. Новизна создаваемой системы заключается в отсутствии систем, в полной мере поддерживающих стандарт TOSCA, в частности, в отсутствии систем, полнофункционально поддерживающих композицию шаблонов [@tomarchio_cloud_2020]. Данная работа ставит целью проектирование функциональной системы, поддерживающей композицию шаблонов с помощью Substitution Mapping и дальнейшее их развёртывание в различных облачных средах.
Создаваемая система должна иметь приложение к реальным задачам. В рамках работы мы ограничиваемся воспроизводимым развёртыванием сервиса Kubernetes. Kubernetes [@noauthor_kubernetes_nodate] — это переносимая расширяемая платформа с открытым исходным кодом для управления контейнеризованными приложениями и сервисами, которая облегчает как декларативную настройку, так и автоматизацию. У платформы есть большая, быстро растущая экосистема. Сервисы, поддержка и инструменты Kubernetes широко доступны. Большое количество дистрибутивов, различие инструментов развёртывания, поддержка всеми облачными провайдерами, а также множество взаимосвязанных компонентов, входящих в состав системы, и делают Kubernetes хорошим кандидатом для рассмотрения.
Не менее интересно проверить, насколько управление жизненным циклом кластеров Kubernetes упростится с применением стандарта TOSCA. Это позволит создавать и поддерживать полностью изолированные, переносимые, обновляемые и воспроизводимые кластеры.
2. Постановка задачи
Здесь надо максимально формально описать суть задачи, которую потребуется решить, так, чтобы можно было потом понять, в какой степени полученное в результате работы решение ей соответствует. Текст главы должен быть написан в стиле технического задания, т.е. содержать как описание задачи, так и некоторый набор требований к решению.
Целью работы является проектирование системы оркестрации, способной воспроизводимо разворачивать платформенные сервисы по декларативным описаниям на языке TOSCA. Главной особенностью создаваемой системы является поддержка композиции шаблонов как главного механизма параметризации сервисов и расширения возможностей самой системы. В будущем это позволит обслуживать полный жизненный цикл TOSCA: моделирование и проектирование сервисов, развёртывание реальной инфраструктуры по описаниям на языке TOSCA, а также выполнение операций, связанных с её жизненным циклом, таких как обновления, масштабирование, миграции.
Демонстрационным примером работоспособности создаваемой в рамках выпускной квалификационной работы платформы является развёртывание сервиса Kubernetes. Необходимо поддержать возможность конфигурации отдельных компонентов, разработать набор описаний на языке TOSCA, позволяющий моделировать кластеры Kubernetes разной сложности, совместимые с несколькими облачными окружениями.
Для достижения поставленной цели необходимо выполнить следующие этапы:
- Исследование
- Изучить возможности и текущие ограничения стандарта TOSCA, по правилам Substitution Mapping описать алгоритм композиции;
- Провести сравнение существующих систем оркестрации, поддерживающих TOSCA;
- Изучить архитектуры существующих дистрибутивов Kubernetes, выделить общие для всех решений возможности конфигурации платформы;
- Практика
- Разработать архитектуру системы оркестрации, описать требования к каждому компоненту;
- Реализовать сервис, осуществляющего композицию шаблонов;
- Разработать набор определений на языке TOSCA для Kubernetes, смоделировать с помощью полученных определений топологию Kubernetes, которая будет являться входом для создаваемой системы оркестрации;
- Оценка решения
- Провести развёртывание кластера Kubernetes в различных конфигурациях на трёх доступных платформах: baremetal, OpenStack и Yandex Cloud;
- Измерить время развёртывания кластера Kubernetes, сравнить с существующими решениями;
- Оценить развёрнутый кластер с помощью сквозных тестов на соответствие требованиям к кластеру Kubernetes @noauthor_vmware-tanzusonobuoy_2023.
3. Обзор существующих решений
Здесь надо рассмотреть все существующие решения поставленной задачи, но не просто пересказать, в чем там дело, а оценить степень их соответствия тем ограничениям, которые были сформулированы в постановке задачи.
TOSCA
Язык TOSCA представляет набор соглашений на основе YAML для создания шаблонов сервисов, определяющих управление жизненным циклом приложений, инфраструктуры и сетевых сервисов.
При определении сервисов с помощью TOSCA мы должны различать четыре вида сущностей:
- Типы (TOSCA types): Типы TOSCA определяют повторно используемые строительные блоки, которые могут быть использованы во время проектирования сервисов. Например, типы узлов TOSCA определяют многократно используемые компоненты сервиса, включая их настраиваемые свойства.
- Шаблоны (TOSCA templates): Шаблоны TOSCA определяют (типизированные) компоненты сервиса. Например, шаблоны сервисов включают шаблоны узлов, которые присваивают определенные значения настраиваемым параметрам, определенным в соответствующих типах узлов. Нередко в шаблоне сервиса имеется несколько шаблонов узлов одного и того же типа узла, например, несколько виртуальных машин, служащих под разные цели.
- Модели представления (TOSCA instance models): Во время развертывания, системы оркестрации TOSCA объединяют шаблоны сервисов TOSCA с входными значениями, специфичными для развертывания, чтобы создать модель представления сервиса, который будет развернут и управляться оркестратором. TOSCA не стандартизирует объектную модель для представлений, такие модели зависят от конкретной реализации.
- Внешние реализации: Это фактические ресурсы и сервисы во внешнем мире, управляемые оркестратором. Информация об этих ресурсах должна синхронизироваться с моделями представления.
В файле TOSCA шаблон сервиса (service template) определяет топологическую модель в виде направленного ациклического графа (DAG). Каждый узел (node) в этом графе представлен шаблоном узла (node template). Шаблон узла определяет объект определенного типа. Тип узла определяет свойства (properties и capabilities) этого компонента, а также зависимости (requirements), связывающие этот узел с другими через отношения (relationships). Типы узлов определяются отдельно для целей повторного использования. В шаблоне сервиса шаблон узла присваивает значения свойствам, определенным в типе узла. Операции (operations), связанные с узлом или отношением узлов, определяют, как этот компонент может быть развёрнут и остановлен, а также как им можно управлять в течение всего времени существования. Выполнение операций может изменять состояние узла, что отражается в изменении его атрибутов (attributes). Операции, связанные с одной и той же задачей управления (например, управление жизненным циклом), группируются в интерфейсы (interfaces).
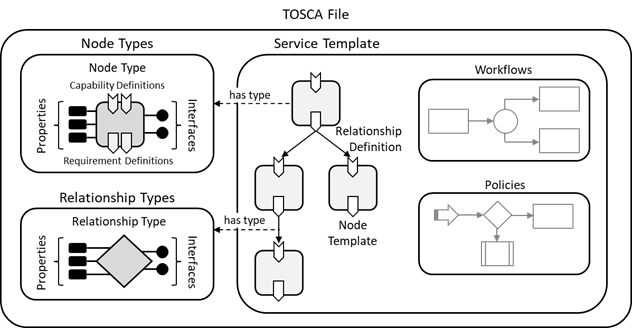
Реализации операций интерфейса могут быть предоставлены в виде артефактов (artifacts). Артефакт представляет собой данные, необходимые для обеспечения реализации операций. Артефактом TOSCA может быть исполняемый файл (например, скрипт, исполняемая программа, изображение), файл конфигурации или файл данных, или что-то, что может быть необходимо для запуска другого исполняемого файла (например, библиотека). Артефакты могут быть разных типов, например, Ansible сценарии или скрипты Python. Содержание артефакта зависит от его типа. Обычно вместе с артефактом предоставляются описательные метаданные (например, свойства). Эти метаданные могут понадобиться для правильной обработки артефакта, например, для описания соответствующей среды выполнения.
В TOSCA определён набор так называемых нормативных типов, определяющих классы широко используемых ресурсов, таких как вычислительные узлы, сети, хранилища и так далее. Эти типы задают общий интерфейс для всех остальных определений на языке TOSCA, обеспечивая их совместимость. Нормативные типы должны поддерживаться каждой TOSCA системой, однако расхождения в определениях нормативных типов могут повлечь проблемы, связанные с несовместимостью. На данный момент актуальной является версия стандарта TOSCA 2.0, находящаяся в разработке. Помимо этого существуют версии TOSCA 1.0, 1.1, 1.2, 1.3, не обладающие полной совместимостью друг с другом и с версией 2.0.
Рассмотрим пример TOSCA шаблона:
tosca_definitions_version: tosca_simple_yaml_1_3
metadata:
template_name: my_template
template_author: me@example.com
template_version: '1.0'
description: Пример шаблона на языке TOSCA
topology_template:
node_templates:
my_server:
type: tosca.nodes.Compute
capabilities:
host:
properties:
mem_size: 16 GiB
disk_size: 512 GiB
num_cpus: 4
os:
properties:
distribution: Ubuntu
В этом примере определен шаблон, который описывает сервер, который может быть развернут в облаке. Шаблон начинается с указания версии TOSCA и метаданных.
Затем определяется topology_template, который содержит node_templates, которые в свою очередь описывают различные компоненты инфраструктуры, необходимые для развертывания приложения. В данном примере описывается только один узел my_server, который представляет сервер.
Узел my_server указывает на тип tosca.nodes.Compute, который является нормативным. С помощью этого типа можно описать как вычислительные узлы подавляющего числа облачных провайдеров, так и физические вычислительные узлы.
TOSCA функции
Стандарт TOSCA позволяет использовать встроенные функции при присваивании значений параметрам и атрибутам. Функции подразделяются на следующие категории:
Функции запроса графа представления
Данные функции позволяют получить значение, содержащееся в другом объекте графа представления. Существует три функции: get_input, get_property и get_attribute, которые позволяют получить значение input, property и attribute соответственно. Грамматика таких вызовов описывается в YAML следующим образом:
get_property:
- <initial_context>
- <rel_context>
- ...
- <rel_context>
Началом является определённый узел или отношение, описанное его символическим именем или специальным ключевым словом SELF, TARGET, SOURCE, HOST. После этого в пути содержатся символические имена объектов относительно текущего положения в обходе. Конечным в обходе является искомое значение, которое и возвращается функцией.
Отдельно стоит выделить функцию get_artifact, позволяющую передать исполняемому артефакту путь к другому, передавая его через input соответствующей операции.
Строковые функции
- Функция
concatпозволяет выполнить конкатенацию нескольких строковых значений - Похожую функциональность выполняет функция
join, однако позволяет передать разделитель, вставляемый между конкатенируемыми строками
Нормализация шаблонов
В TOSCA часто допустимо несколько нотаций для описания сущности: короткая и более развёрнутая. Например, requirement можно описать двумя способами:
requirements:
# Расширенная нотация
- host:
node: node_template_name
capability: host
relationship: tosca.relationships.HostedOn
# Сжатая нотация
- host: node_template_name
Это упрощает процесс создания шаблона TOSCA, так как лишает необходимости писать излишне подробные описания, но усложняет работу с шаблоном на последующих этапах. Для решения этой проблемы требуется ввести понятие нормализации шаблона. Цель нормализации в том, чтобы части системы, работающие с TOSCA, не занимались разбором нотаций и валидацией типов.
Композиция шаблонов
Детальное описание сложной системы на языке TOSCA в одном шаблоне потребует описания большого количества узлов и параметров, в растущей сложности которых полученное описание станет сложно поддерживать. Встаёт острая необходимость в механизме декомпозиции таких больших описаний на несколько шаблонов, описывающих разные части системы, и в механизме их последующей композиции. Для решения обозначенной проблемы, авторы стандарта вводят механизм Substitution Mapping.
Substitution mapping - это мощная концепция TOSCA, которая позволяет рассматривать шаблон как один многократно используемый узел. Например, вы можете смоделировать сложный кластер Hadoop так, что другие люди смогут использовать тонко настроенную установку Hadoop, даже не подозревая о всей сложности системы, лежащей в основе.
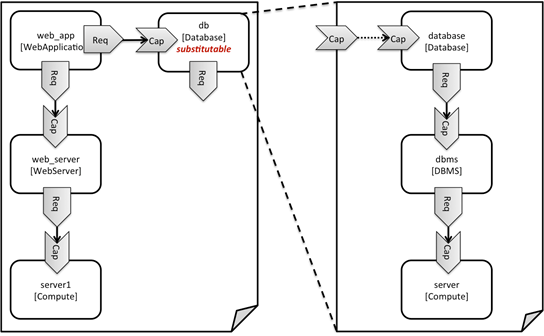
Узлы шаблона, которые необходимо заместить, помечаются директивой substitute:
tosca_definitions_version: tosca_simple_yaml_1_3
imports:
- my_types.yaml
topology_template:
node_templates:
abstract_app:
type: App
directives: [ substitute ]
properties:
config_path: /etc/app/config.yaml
capabilities:
endpoint:
properties:
port: 80
Директивы предназначены для системы оркестрации. В частности, директива substitute означает, что в момент развёртывания шаблона, система должна подставить вместо помеченного узла другую известную топологию. Механизм выбора подстановки не описывается стандартом TOSCA, он может быть как ручным (пользователь выбирает одну из опций), так и автоматическим.
Шаблоны, подходящие для подстановки, описываются следующим образом:
tosca_definitions_version: tosca_simple_yaml_1_3
imports:
- my_types.yaml
topology_template:
inputs:
config_path:
type: string
node_templates:
my_app:
type: MyApp
properties:
config_path: { get_input: [ config_path ] }
requirements:
- host: compute
compute:
type: tosca.nodes.Compute
substitution_mappings:
node_type: App
properties:
config_path: [ config_path ]
capabilities:
endpoint: [ my_app, endpoint ]
Здесь, в секции substitution_mapping описано, как параметры подменяемого узла отобразятся на параметры подменяющей топологии. В стандарте сказано, что properties переходят в inputs, attributes — в outputs, а requirements и capabilities передаются подменяющим узлам в соответствии с правилами отображения.
Описанный выше интерфейс, заданный типом App, можно реализовать и другим образом:
tosca_definitions_version: tosca_simple_yaml_1_3
imports:
- my_types.yaml
topology_template:
inputs:
config_path:
type: string
node_templates:
my_app_frontend:
type: Frontend
requirements:
- host: frontend_host
frontend_host:
type: tosca.nodes.Compute
my_app_backend:
type: Backend
properties:
config_path: { get_input: [ config_path ] }
requirements:
- host: backend_host
backend_host:
type: tosca.nodes.Compute
substitution_mappings:
node_type: App
properties:
config_path: [ config_path ]
capabilities:
endpoint: [ my_app_frontend, endpoint ]
Второй шаблон описывает другую топологию приложения, являясь при этом валидной подменой узла app в верхнеуровневом шаблоне.
Главным правилом создания шаблонов, подменяющих абстрактные узлы, является их независимость от Substitution Mapping. То есть, создаваемый шаблон должен являться самодостаточной единицей развёртывания и не зависеть от шаблонов, куда он подставляется.
Стоит отметить, что стандарт TOSCA документирует лишь синтаксис отображения, но не документирует механизм разрешения конфликтов. Например, в подставляемом шаблоне в параметрах, на которые отображаются значения из подменяемого узла, могут содержаться значения. В таком случае нужно описать механизм принятия решения, какое значение будет подставлено в результате. Другим примером является отображение requirements на те узлы, где эти requirements уже выставлены.
Главной задачей дальнейшей работы является рассмотрение краевых случаев реализации Substitution Mapping, разработка алгоритма отображения.
Специализация шаблонов
В стандарте TOSCA 2.0 шаблоны подразделяются на две категории: профили и реализации сервисов.
Профиль - это именованная коллекция определений типов TOSCA, артефактов и шаблонов сервисов, которые логически принадлежат друг другу, относятся к одной предметной области. Профили TOSCA можно рассматривать как библиотеки, предоставляемые конкретной платформой и доступные всем сервисам, использующим эту платформу. Сущности, определенные в профилях TOSCA, используются следующим образом:
- Типы, определенные в профиле TOSCA, представляют собой многократно используемые строительные блоки, из которых можно составлять сервисы.
- Артефакты и шаблоны сервисов, определенные в профиле TOSCA, обеспечивают реализацию типов, определенных в профиле. В то время как артефакты обеспечивают реализацию интерфейсных операций для конкретных узлов и отношений, шаблоны сервисов, определенные в профилях TOSCA, предназначены для реализации абстрактных узлов через Substitution Mapping.
Ниже приведён пример профиля, описывающего специализацию абстрактного Compute узла под облачного провайдера OpenStack:
tosca_definitions_version: tosca_simple_yaml_1_3
node_types:
openstack.nodes.Server:
derived_from: openstack.nodes.Root
attributes:
# omitted for brevity
properties:
name:
type: string
requirements:
- flavor:
capability: openstack.capabilities.Node
node: openstack.nodes.Flavor
relationship: openstack.relationships.DependsOn
occurrences: [ 1, 1 ]
- image:
capability: openstack.capabilities.Node
node: openstack.nodes.Image
relationship: openstack.relationships.DependsOn
occurrences: [ 1, 1 ]
# rest omitted for brevity
interfaces:
create:
implementation: create_playbook
artifacts:
create_playbook:
type: tosca.artifacts.Implementation.Ansible
file: /path/to/playbook.yaml
Реализации же описывают шаблоны конкретных платформ, представляющие полную архитектуру и взаимосвязи между компонентами. Реализации как правило используют несколько профилей для описания конкретной системы.
Рассмотрим наиболее простой пример реализации:
tosca_definitions_version: tosca_simple_yaml_1_3
description: Template for deploying a single server with predefined properties.
topology_template:
node_templates:
my_server:
type: tosca.nodes.Compute
directives: [ substitute ]
capabilities:
host:
properties:
num_cpus: 1
disk_size: 10 GB
os:
properties:
type: linux
distribution: ubuntu
version: 20.04
Здесь описан один логический узел Compute с зафиксированными свойствами вычислительного узла и операционной системы. Тип tosca.nodes.Compute является нормативным и должен поддерживаться каждой системой оркестрации TOSCA, так как является обобщением широкого класса повсеместно используемых ресурсов. С помощью tosca.nodes.Compute можно описать как вычислительные узлы подавляющего числа облачных провайдеров, так и физические вычислительные узлы.
В момент развёртывания этого шаблона оркестратор может взять специализацию под OpenStack как возможную подстановку и осуществить её, превратив абстрактное описание вычислительного узла в конкретное. Здесь и реализуются сильные стороны механизма подстановки: всё знание об облачных платформах содержится в описаниях TOSCA и не привязано к системе оркестрации.
И профили, и реализации могут состоять из нескольких файлов YAML, а также связанных с ними артефактов исполнения. Для удобства передачи таких взаимосвязанных коллекций файлов в стандарте выделен формат TOSCA Cloud Service Archive (CSAR). CSAR - это zip-файл, в котором могут быть упакованы определения TOSCA вместе со всеми сопутствующими артефактами.
CSAR должен содержать один из следующих файлов:
- Файл метаданных TOSCA.meta, который предоставляет информацию о входе для оркестратора TOSCA, обрабатывающего файл CSAR. Файл TOSCA.meta может быть расположен либо в корне архива, либо внутри каталога TOSCA-Metadata (каталог находится в корне архива). CSAR может содержать только один файл TOSCA.meta.
- файл YAML в корне архива, являющийся действительным шаблоном определения tosca.
Операционная модель
Стандарт TOSCA 2.0 описывает следующую операционную модель:
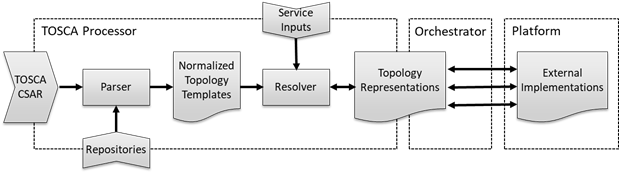
TOSCA processor является ключевой частью TOSCA инфраструктуры, главной задачей которого является преобразование шаблонов на языке TOSCA к модели представления топологии. TOSCA processor состоит из следующих компонентов:
- Parser - система синтаксического разбора и последующей нормализации и валидации TOSCA шаблонов
- Resolver - система наполнения модели представления представления. Основными ответственностями этой системы являются контроль зависимостей между узлами и выбора конкретных реализаций по абстрактным описаниям.
Orchestrator является связующим звеном между внутренним представлением топологии и реальными сервисами. Его основная задача — выполнение операций над сервисами и обновление внутреннего представления в соответствии с их состоянием.
TOSCA анализаторы
Язык TOSCA гибок и порой неоднозначен, что делает его непростым объектом для синтаксического анализа. Несмотря на то, что набор правил описания шаблонов стандартизирован, не существует формальной грамматики для разбора, что осложняется небольшими отклонениями в версиях стандартов.
Система оркестрации должна выполнять валидацию и нормализацию поступающих к ней шаблонов на языке TOSCA. В данном разделе рассмотрены основные реализации абстракции Parser.
OpenStack TOSCA parser
TOSCA Parser - это инструмент с открытым исходным кодом, который разрабатывается командой OpenStack и предназначен для обработки шаблонов TOSCA.
TOSCA Parser может использоваться для чтения и анализа файлов TOSCA, а также для валидации TOSCA-описаний. Он может читать файлы TOSCA в формате YAML и преобразовывать их в объекты Python, которые могут быть использованы для автоматизации процесса развертывания и управления приложениями.
Рассматриваемый анализатор используется в оркестраторах Cloudify и Clouni. Он также может использоваться в других инструментах в качестве встраиваемой Python библиотеки. Однако, TOSCA Parser медленно развивается. На данный момент анализатор поддерживает стандарт TOSCA 1.2, в то время как работа над стандартом TOSCA 2.0 почти завершена.
Дополнительно стоит отметить ограниченные возможности валидации: при подаче неправильно сформированного YAML файла, анализатор завершается с ошибкой и печатает стек исполнения. Такой информации недостаточно, чтобы определить, в каком месте шаблона совершена ошибка.
Opera TOSCA parser
Opera TOSCA parser тоже открыт и поставляется в виде Python библиотеки, способной отображать содержимое TOSCA YAML файлов в объекты Python. Данный анализатор используется только в одноимённой системе оркестрации Opera, выполняя задачу нормализации. По сравнению с OpenStack parser, анализатор Opera развивается быстрее, разрабатывается более маленькой командой, чем сообщество OpenStack.
Opera parser поддерживает TOSCA версии 1.3, но так же лишён возможности валидации, показывая поведение, схожее с OpenStack parser.
Puccini
Puccini - это инструмент для обработки файлов TOSCA, разрабатываемый Tal Liron. Поставляется с тремя CLI инструментами: puccini-tosca, puccini-csar и puccini-clout. Первый инструмент предназначен как раз для синтаксического анализа TOSCA и дальнейшей нормализации. Основными командами являются puccini-tosca parse и puccini-tosca compile. Первая команда проверяет синтаксис TOSCA-описаний на наличие ошибок и несоответствий стандарту, выводя развёрнутый список ошибок их локаций в файле. При отсутствии ошибок, выводом команды является нормализованное представление шаблона, расширенное описанием типов. Вторая команда приводит шаблон к формату Clout [ссылка], выполняющему роль модели представления.
Основными расширениями в модели [ссылка], представляющей нормализованный шаблон, являются:
- Хранение полной иерархии наследования для типизированных объектов по ключу
types. Это позволяет выполнять проверку на принадлежность объекта к тому или иному типу, не обращаясь к системе анализа; - Расширенная модель хранения значений: рядом с каждым значением атрибутов и параметров хранится его тип;
- Плоское хранение requirements: формат описания requirements в виде списка словарей с единственным ключом, обозначающим имя, неудобен для разбора, так как требует выяснения имени ключа и последующего обращения по нему; Puccini реализует плоскую модель хранения списка словарей с заданной схемой ключей, одним из которых является имя.
Формат Clout во многом наследует структуру данных нормализованной модели, однако унифицирует всё в графовом представлении, допускающем последующую совместимость и с другими языками высокоуровневого моделирования.
К дополнительным особенностям можно отнести:
- Преобразование в другие форматы: Puccini может преобразовывать TOSCA-описания в другие форматы, такие как JSON или YAML;
- Встраиваемость: Puccini доступен в виде библиотеки на языке Go и в виде CLI-инструмента, может быть использован в качестве библиотеки Python, а также может быть встроен в WebAsm приложения;
- Гибкость: В интерфейс анализатора встроена поддержка разночтений стандарта TOSCA, называемая
quirks, что позволяет настроить его под конкретную интерпретацию.
Открытость, актуальность и простота использования данного инструмента делают его отличным кандидатом для задач валидации и нормализации шаблонов.
TOSCA оркестраторы
Раздел посвящён сравнительному анализу систем оркестрации, поддерживающих композицию шаблонов. Среди систем оркестрации, поддерживающих TOSCA, таких как Cloudify, xOpera, OpenTOSCA, INDIGO, Khutulun и других [@noauthor_philippemerletosca-implementation-landscape_nodate], сравнительно немного систем поддерживает Substitution Mapping или аналогичный механизм.
Alien4Cloud
Платформа Alien4Cloud позволяет управлять полным жизненным циклом сервисов, используя TOSCA. Архитектура платформы выглядит следующим образом:
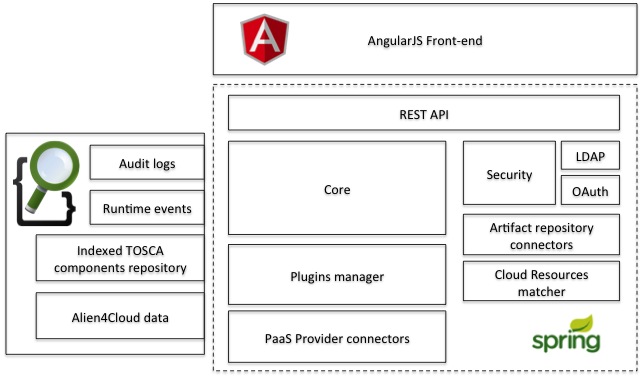
Сервис содержит такие компоненты как:
- Frontend, через который осуществляется взаимодействие пользователя с разворачиваемой инфраструктурой и TOSCA описаниями
- Core сервис, представляющий собой монолитное приложение, работающее с метамоделью TOSCA
- Набор плагинов, позволяющих Alien4Cloud работать с
- Оркестраторами cloudify, yorc, puccini
- Хранилищем секретов HashCorp Vault
- Также в Alien4Cloud реализована функция мониторинга.
Alien4Cloud предоставляет возможность самостоятельного размещения их платформы на собственных серверах через развёртывание Docker контейнеров или через запуск сценариев Ansible. После запуска платформы, можно загрузить на неё существующие TOSCA описания через загрузку TOSCA шаблонов на сайт через пользовательский интерфейс или через синхронизацию с репозиторием git.
Платформа оснащена графическим интерфейсом, позволяющим моделировать приложения TOSCA.
Важно отметить, что Alien4Cloud не поддерживает официальный TOSCA simple profile начиная с версии 1.0. Вместо этого, поддерживается так называемый AlienDSL, развиваемый параллельно. Из-за этого настоящая версия AlienDSL 3.0 хоть и близка к разрабатываемому в настоящее время стандарту TOSCA версии 2.0, но не совместима с ним, что не позволяет использовать описания на AlienDSL с другими инструментами, поддерживающими TOSCA, что полностью нивелирует преимущества стандартизации.
В качестве примеров, отличающих язык AlienDSL от нормативного языка TOSCA, можно привести описание артефактов:
# AlienDSL
node_types:
fastconnect.nodes.OperationSample:
artifacts:
- scripts_directory: scripts
type: tosca.artifacts.File
description: Directory that contains all scripts
# TOSCA
node_types:
fastconnect.nodes.OperationSample:
artifacts:
scripts_directory:
file: scripts
type: tosca.artifacts.File
description: Directory that contains all scripts.
Несмотря на небольшие расхождения с TOSCA, Alien4Cloud поддерживает композицию шаблонов с помощью Substitution Mapping.
Такой подход позволяет объединять несколько шаблонов, однако выбор конкретной реализации осуществляется в момент создания шаблона, а не в момент его развёртывания. Это делает создаваемые шаблоны специфичными под конкретную облачную среду лишая возможности использования в других облачных средах.
Во время выполнения данной работы стало известно об окончании поддержки системы Alien4Cloud в декабре 2022 года.
Turandot
Turandot - это система автоматизации развертывания и управления приложениями, основанная на контейнерной оркестрации Kubernetes. Turandot основан на Puccini и работает с представлением Clout, что позволяет делегировать большое число операций над графом TOSCA сервису Puccini.
Turandot был разработан для работы в среде Kubernetes и полностью заточен под эту технологию. Он использует API Kubernetes для автоматизации развертывания, управления и масштабирования контейнерных приложений, что делает его удобным и знакомым для пользователей, работающих с этой платформой. Тем не менее, такая особенность ограничивает выбор платформенного провайдера и требует наличия развёрнутой отдельно платформы Kubernetes.
В документации системы заявлена поддержка композиции шаблонов, однако реализация не соответствует заявленному: правила композиции определяются с помощью ненормативных типов, поддерживается композиция только заранее заданных шаблонов.
Ubicity
Ubicity - это основанный на TOSCA оркестратор с закрытым исходным кодом, который поддерживает развертывание и активацию сервисов, последующее управление сервисами и их деактивацию. Ubicity является доменно-независимым, что означает, что его можно использовать для различных доменов приложений, а также для сервисов, которые охватывают несколько доменов приложений.
Ubicity включает следующие компоненты:
- Lifecycle Manager, который выполняет все функции управления жизненным циклом сервисов, включая декомпозицию сервисов, запуск сценариев и автоматизацию на основе политик. Все действия по управлению жизненным циклом сначала выполняются на внутреннем представлении топологии, а затем синхронизируются с реальными компонентами и ресурсами сервиса во внешнем мире.
- Service Instance Model Inventory, в котором хранятся представления всех сервисов, управляемых Ubicity. Все действия по управлению жизненным циклом работают на этой модели.
- Service Catalog, в котором хранится набор развертываемых сервисов. Разработчики сервисов включают в каталог архивы сервисов, содержащие модели сервисов и связанные с ними артефакты управления жизненным циклом. Конечный пользователь выбирает сервис из этого каталога при развертывании новых сервисов.
- Resource Inventory, который хранит и управляет доступными ресурсами, на основе которых могут быть развернуты сервисы. Поставщики ресурсов используют модели ресурсов на основе TOSCA для включения своих ресурсов в каталог ресурсов. Примерами типов ресурсов, которые могут быть добавлены, являются облака IaaS, кластеры Kubernetes, сети SDN, устройства uCPE, физические серверы и т.д.
- Profile Library, предоставляющая коллекции многократно используемых компонентов, на основе которых могут быть созданы шаблоны сервисов. Эксперты домена организуют свои модели компонентов услуг, специфичные для домена, в профили, которые затем могут быть представлены и сохранены в библиотеке профилей.
Важной особенностью Ubicity является фокус на использовании TOSCA substitution mapping. Это позволяет создавать высокоуровневые шаблоны сервисов, представляющие абстрактные описания, которые скрывают детали реализации и технологии. Во время развертывания Ubicity подставляет вместо абстрактных сервисов субкомпоненты, специфичные для технологии и поставщика, используя функцию TOSCA substitution mapping. Выбор субкомпонентов зависит от доступных ресурсов, политик или предпочтений пользователя.
Главным недостатком платформы является её закрытость. На данный момент доступ к системе оркестрации возможен только по корпоративному запросу.
Clouni
Clouni (разработка ИСП РАН) - это TOSCA мультиоблачный оркестратор уровня IaaS провайдеров OpenStack, Amazon, Kubernetes. Основная особенность этого инструмента - возможность трансляции нормативных компонентов TOSCA шаблонов в ненормативные, зависящие от облачного провайдера.
Clouni поддерживает только Ansible сценарии в качестве исполняемых артефактов, позволяя развернуть описанную в модели TOSCA топологию с помощью сервиса GRPC Cotea, о котором будет рассказано дальше в обзоре. Clouni поддерживает параллельное развёртывание независимых узлов с соблюдением порядка зависимостей, заданных как явно через relationships, так и неявно через язык запросов TOSCA функций.
Данная система основывается на версии TOSCA 1.0 и частично поддерживает TOSCA 1.3. В качестве анализатора используется OpenStack TOSCA parser.
Clouni не поддерживает substitution mapping, однако реализует собственный механизм тонкой настройки под конкретного облачного провайдера, что включает конфигурацию виртуальных машин, сетей и групп безопасности. На данный момент поддерживаются такие облачные провайдеры как OpenStack, Amazon, Kubernetes. Для добавления новой системы необходимо описать файл с правилами отображения по определённому набору правил. Это является основным недостатком по сравнению с substitution mapping, так как формат описания отображений в clouni сложен и требует дополнительной квалификации.
xOpera
xOpera является легковесной открытой системой оркестрации, разрабатываемой на языке Python. На данный момент стабильно поддерживается стандарт TOSCA 1.3, разбор которого в данной системе выполняет Opera TOSCA parser.
В качестве исполняемых артефактов поддерживаются только Ansible сценарии. xOpera также поддерживает параллельное развёртывание узлов аналогично Clouni.
Несмотря на то, что оркестратор xOpera не поддерживает механизм substitution mapping, он является минималистичным и поставляется в виде модуля Python. Это и широкая поддержка стандарта TOSCA 1.3 позволяют использовать xOpera в качестве отладочной системы, выполняющей все базовые операции над моделью TOSCA.
%%### Michman
Michman – это орекстартор, разработанный в ИСП РАН. Он состоит из двух подсистем: michman-rest и michman-launcher, использует реляционную систему управления базами данных MySQL и хранилище секретов Vault, а также тесно взаимодействует с сервисами OpenStack, авторизуясь в качестве служебного пользователя Keystone.
Cotea
==Обзор Cotea==%%
Kubernetes
В качестве платформы, моделируемой с помощью TOSCA, выбран Kubernetes. Существуют работы, посвящённые описанию объектов в кластере Kubernetes с помощью TOSCA [ссылки], в том числе подобную задачу решает оркестратор Turandot. Данная же работа ставит целью исследование моделирования самой платформы Kubernetes в выбранной версии и с выбираемыми архитектурными вариантами для развёртывания на множестве узлов в разных облачных окружениях.
Kubernetes — это переносимая расширяемая платформа с открытым исходным кодом для управления контейнеризованными приложениями и сервисами, которая облегчает как декларативную настройку, так и автоматизацию. У платформы есть большая, быстро растущая экосистема. Сервисы, поддержка и инструменты Kubernetes широко доступны.
Kubernetes предоставляет вам:
- Мониторинг сервисов и распределение нагрузки Kubernetes может обнаружить контейнер, используя имя DNS или собственный IP-адрес. Если трафик в контейнере высокий, Kubernetes может сбалансировать нагрузку и распределить сетевой трафик, чтобы развертывание было стабильным.
- Оркестрация хранилища Kubernetes позволяет вам автоматически смонтировать систему хранения по вашему выбору, такую как локальное хранилище, провайдеры общедоступного облака и многое другое.
- Автоматическое развертывание и откаты Используя Kubernetes можно описать желаемое состояние развернутых контейнеров и изменить фактическое состояние на желаемое. Например, вы можете автоматизировать Kubernetes на создание новых контейнеров для развертывания, удаления существующих контейнеров и распределения всех их ресурсов в новый контейнер.
- Автоматическое распределение нагрузки Вы предоставляете Kubernetes кластер узлов, который он может использовать для запуска контейнерных задач. Вы указываете Kubernetes, сколько ЦП и памяти (ОЗУ) требуется каждому контейнеру. Kubernetes может разместить контейнеры на ваших узлах так, чтобы наиболее эффективно использовать ресурсы.
- Отказоустойчивость Kubernetes перезапускает отказавшие контейнеры, заменяет и завершает работу контейнеров, которые не проходят определенную пользователем проверку работоспособности, и не показывает их клиентам, пока они не будут готовы к обслуживанию.
Компоненты кластера
Кластер Kubernetes состоит из машин, так называемых узлов, которые запускают контейнеризированные приложения. Кластер имеет как минимум один рабочий узел.
В рабочих узлах размещены поды, являющиеся компонентами приложения. Плоскость управления управляет рабочими узлами и подами в кластере. В промышленных средах плоскость управления обычно запускается на нескольких компьютерах, а кластер, как правило, развёртывается на нескольких узлах, гарантируя отказоустойчивость и высокую надёжность.
Ниже показана диаграмма кластера Kubernetes со всеми связанными компонентами.
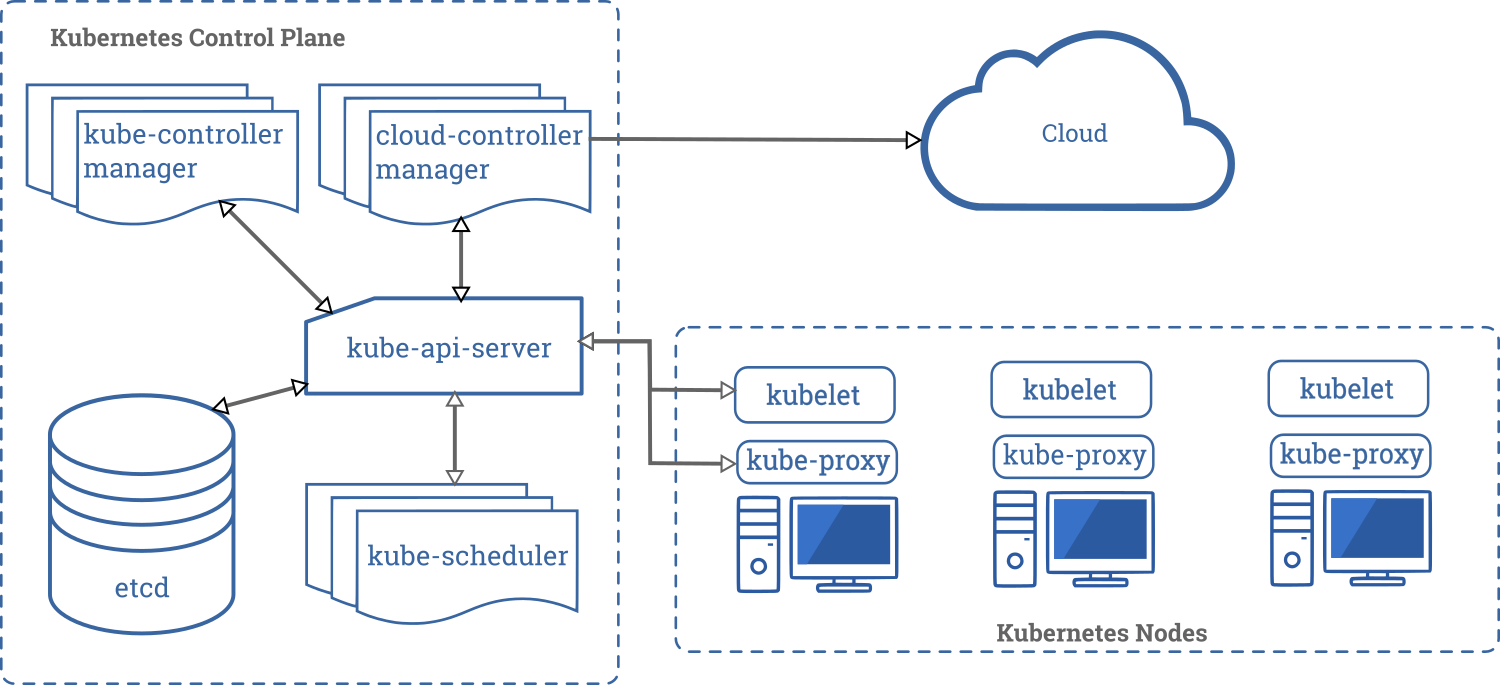
Ключевыми компонентами архитектуры Kubernetes являются:
- Control plane: управляет кластером Kubernetes. Включает в себя пять основных компонентов:
- API Server: центральный компонент, который предоставляет API для управления кластером;
- Controller Manager: отслеживает состояние кластера и запускает необходимые действия, если что-то не работает должным образом;
- Cloud Controller Manager: отвечает за подключение ко внешним облачным провайдерам для получения доступа к их ресурсам;
- Scheduler: отвечает за распределение нагрузки по имеющимся узлам;
- etcd: надежное, распределенное key-value хранилище, используемое для хранения состояния кластера.
- Node: это вычислительный узел в кластере, на котором запускаются контейнеры. Он состоит из двух основных компонентов:
- Kubelet: компонент, который управляет контейнерами на Node, запускает их, останавливает и контролирует их состояние;
- kube-proxy: компонент, который управляет сетевой связью между контейнерами внутри Node и с остальными компонентами Kubernetes.
Все компоненты Kubernetes тесно взаимодействуют друг с другом и обмениваются информацией для обеспечения высокой доступности и отказоустойчивости. Когда приложение запускается, оно описывается с помощью YAML-файла, который загружается в API-сервер Kubernetes. Кластер Kubernetes затем переводит этот файл в операции создания и настройки контейнеров, которые будут работать в кластере. Control plane обеспечивает управление этими операциями, а узлы выполняют их.
Среды исполнения контейнеров (CRI)
Среда исполнения контейнеров - это программное обеспечение, которое отвечает за запуск контейнеров. Ранее Kubernetes использовал Docker в качестве такой среды, но было решено унифицировать интерфейс работы с контейнерами для поддержки других возможных сред. Этот интерфейс получил название CRI (Container Runtime Interface). Сейчас Kubernetes поддерживает такие контейнерные среды выполнения, как containerd, CRI-O и любые другие реализации CRI.
При развёртывании кластера Kubernetes, необходимо зафиксировать среду исполнения, устанавливаемую на каждом рабочем узле рядом с сервисом Kubelet. Помимо этого, каждая реализация CRI совместима с интерфейсами OCI.
==сказать, что это точка кастомизации==
==сказать про oci==
Настройка сети (CNI)
==расписать==
Развёртывание Kubernetes
Open source Kubernetes не указывает конкретный инструмент установки и оставляет многие варианты конфигурации установки на усмотрение пользователя.
Хотя использование Kubernetes со временем стало проще, поиск и использование систем установки с открытым исходным кодом может быть затруднительным. Пользователям необходимо понять, какие версии использовать, где их взять и совместим ли тот или иной компонент с другим. Им также необходимо решить, какое программное обеспечение будет развернуто на их кластерах и какие настройки использовать для обеспечения безопасности, стабильности и эффективности их платформ. Все это требует глубоких знаний в области Kubernetes, которые могут быть недоступны в компании.
Дистрибутивы Kubernetes
Дистрибутивы Kubernetes обеспечивают надежный и проверенный способ установки Kubernetes и предоставляют согласованные настройки по умолчанию, которые создают лучшую и более безопасную операционную среду. Дистрибутив Kubernetes дает поставщикам и проектам контроль и предсказуемость, необходимые для обеспечения поддержки клиентов на протяжении всего жизненного цикла развертывания, обслуживания и обновления кластеров Kubernetes.
Такая предсказуемость позволяет поставщикам дистрибутивов поддерживать пользователей при возникновении производственных проблем. Дистрибутивы также часто предоставляют протестированный и поддерживаемый путь обновления, который позволяет пользователям поддерживать свои кластеры Kubernetes в актуальном состоянии. Кроме того, дистрибутивы часто предоставляют программное обеспечение для развертывания поверх Kubernetes, что упрощает его использование.
Дистрибутивы значительно облегчают и ускоряют внедрение Kubernetes. Поскольку знания, необходимые для конфигурирования и тонкой настройки кластеров, заложены в платформу, организации могут начать работу с “облачными” инструментами без привлечения дополнительных инженеров со специальными знаниями.
- k3s
- rke
- kubesphere
- platform9
- openshift/OKD
Для дистрибутивов Kubernetes можно выделить общие проблемы:
- Хоть на начальном этапе работы с Kubernetes такие решения могут быть допустимы, операции второго дня могут быть затруднены тем, что
- Возможности расширения платформы полностью зависят от разработчиков дистрибутива (В то время как создаваемое решение позволит расширять платформу за счёт возможностей TOSCA)
- Поддержка платформы зависит от дистрибутива (Сложно перейти на другой дистрибутив при прекращении поддержки)
Системы установки Kubernetes
Подобно дистрибутивам Kubernetes, программы установки Kubernetes упрощают начало работы с Kubernetes. Открытый исходный код Kubernetes полагается на такие программы установки, как kubeadm, чтобы запустить кластеры Kubernetes.
Установщики Kubernetes облегчают процесс установки Kubernetes. Как и дистрибутивы, они предоставляют проверенный источник исходного кода и версии. Они также часто поставляются с готовыми конфигурациями окружения Kubernetes. Такие программы установки Kubernetes, как kind (Kubernetes в Docker), позволяют получить кластер Kubernetes с помощью одной команды.
- kubeadm
- kubespray
- kops
- kubekey
- kind

- minikube
Для систем установки можно выделить общие проблемы:
- Системы установки более низкоуровневые и тоже требуют создания некоторой инфраструктуры вокруг них при создании нового кластера
- Системы установки не отвечают за создаваемый слой IaaS, за ним должны следить отдельные специалисты
- Системы установки не взаимозаменяемы, нужно переносить конфигурации
Kubernetes как сервис
Cloud lock:
- amazom EKS
- google GKE
- azure AKS
Hybrid:
- vmware tanzu
Kubernetes as a Service может помочь организациям использовать лучшие возможности Kubernetes, не сталкиваясь со сложностями, связанными с управлением операциями. KaaS может помочь решить целый ряд задач, включая настройку Kubernetes и всех необходимых CI/CD конвейеров, а также мониторинг и управление работой, обеспечение высокой доступности и выпуск обновлений по мере необходимости.
Ключевыми достоинствами KaaS являются:
- Непрерывный мониторинг - KaaS предоставляет централизованные и настраиваемые информационные панели, отслеживающие метрики и дающие представление о состоянии кластера.
- Управление плоскостью управления - KaaS решения берут на себя управление компонентами плоскости управления Kubernetes, такими как etcd, API Server и так далее, обеспечивая их высокую доступность, масштабируемость и отказоустойчивость.
- Безопасность- KaaS решения развертывают Kubernetes со встроенными методами обеспечения безопасности, однако их реализация скрыта от пользователя и является ответственностью провайдера.
Для KaaS общими проблемами являются:
- Vendor lock
- ==Обновления==
- ==Переносимость==
- ==Масштабируемость==
- ==Доступ==
TOSCA для Kubernetes
Большинство найденных описаний на языке TOSCA, работающих с Kubernetes, нацелены разворачивать сервисы поверх существующей платформы.
==Расписать, кто умеет деплоить кубер (cloudify, alien4cloud, ubicity)==
4. Исследование и построение решения задачи
Здесь надо декомпозировать большую задачу из постановки на подзадачи и продолжать этот процесс, пока подзадачи не станут достаточно простыми, чтобы их можно было бы решить напрямую (например, поставив какой-то эксперимент или доказав теорему) или найти готовое решение.
Создаваемая система оркестрации должна обслуживать полный жизненный цикл TOSCA, а именно:
- Моделирование. TOSCA используется для создания “профилей” многократно используемых, композиционно совместимых типов, которые вместе позволяют описывать валидную модель для целевой области. Профили TOSCA значительно упрощают работу разработчика шаблонов сервисов.
- Проектирование. Архитекторы составляют шаблоны сервисов из моделей, предоставляемых профилями TOSCA, либо путем написания TOSCA вручную, либо с помощью графической среды разработки (создание которой выходит за рамки данной работы).
- Развёртывание. Шаблоны сервисов готовы к использованию. Пользователи создают, настраивают и разворачивают топологии сервисов с помощью системы оркестрации TOSCA.
- Облачно-нативные операции. После запуска сервисы должны сами себя оркестрировать, адаптируясь к изменяющимся внутренним и внешним условиям, а также к запущенным и ручным действиям со стороны операторов. Изменения включают масштабирование, восстановление, миграцию, а также более сложные преобразования.
В данном разделе будет представлено описание архитектуры и функциональности создаваемой системы оркестрации. Будут рассмотрены ключевые компоненты системы и их взаимодействие, а также процессы проектирования, развертывания и обслуживания инфраструктуры через плоскость TOSCA.
Модель данных
Для дальнейшего описания функций системы, необходимо зафиксировать модель данных, на которую она будет опираться. Из спецификации TOSCA и её операционной модели следует необходимость поддержки следующих видов данных:
- TOSCA шаблоны - YAML спецификации, соответствующие стандарту TOSCA, содержащие информацию о типах и шаблонах топологий;
- Артефакты - это файлы (сценарии исполнения, образы виртуальных машин и т.п.), необходимые для выполнения операций над развёрнутым окружением;
- Отдельно стоит выделить секреты. Это конфиденциальная информация (SSH ключи, пароли и т.п.), скрытая из публичных источников данных, необходимая для выполнения операций над развёрнутым окружением.
Также стоит выделить CSAR, однако поддержка архивов не является приоритетом.
TOSCA шаблоны следует подразделить на две категории по специализации: профили, реализации сервисов. Также стоит разделять шаблоны TOSCA на нормализованные (используемые внутри системы) и ненормализованные (поступающие от внешних пользователей).
Основными операциями над TOSCA шаблонами являются валидация, нормализация и композиция. В создаваемой программной реализации необходимо предусмотреть интерфейсы для выполнения этих операций.
Стандарт TOSCA описывает лишь метамодель описаний и не фиксирует модель представления, так как это зависит от конкретных требований пользователей и разработчиков. Поэтому необходимо разработать формат для хранения информации о развёрнутых окружениях.
Модели представлений
Создаваемая система должна быть гибкой и расширяемой, применимой к большому количеству предметных областей. Поэтому разумным является использование модели TOSCA для хранения модели представления. Главным преимуществом такого подхода является унифицированный подход к работе с моделью: общие для всех задач операции с моделью TOSCA можно хранить в библиотеке и использовать её во всех компонентах платформы. Это же решение накладывает ограничение в выборе языка для реализации подобной библиотеки: она должна быть легко встраиваема.
Основными операциями над развёрнутым окружением являются выполнение операций и обновление атрибутов узлов и отношений. Так как модель TOSCA позволяет задавать связи между параметрами через функции get_property и get_attribute, необходимо поддерживать эти связи и в модели представлений. Это нужно для того, чтобы обновление атрибутов после выполнения операций над узлами в модели представлений влекло изменение зависимых параметров. Например, развёртывание вычислительного узла влечёт наполнение представления узла Compute значениями private_address и public_address, которые нужны зависимым сервисам для настройки коммуникации.
Поддержание связей в модели представления влечёт необходимость динамически вычислять значения атрибутов. Необходимо реализовать интерфейс для обновления атрибутов и вычисления зависимых от них значений.
Подстановка значений в модели представлений
При переводе шаблона в модель представления, в него необходимо подставить значения, введённые пользователем или выбранные автоматически. TOSCA допускает две точки конфигурации: ввод inputs и выбор реализаций для узлов, помеченных директивой substitute. В зависимости от реализации интерфейса, необходимо предусмотреть возможность передачи этих решений от пользователя системе, составляющей модель представления.
Роли пользователей
Для описания функций платформы необходимо описать роли пользователей, работающих с ней:
Клиент - пользователь, который нуждается в XaaS услугах. Ему не нужна глубокая детализация настройки, основной мотивацией использования платформы является получение услуги по запросу; Оператор - пользователь, который работает с платформой на уровне TOSCA, наполняет реестр доступных для развёртывания сервисов, разрабатывая профили, реализации сервисов и артефакты к ним; Администратор - пользователь, основной целью которого является администрирование инфраструктуры, отслеживание состояние платформы;
Функциональные требования
Набор функциональных требований непосредственно вытекает из жизненного цикла TOSCA:
- Клиент:
- может получить все TOSCA шаблоны, моделирующие заданный сервис;
- может создать окружение по TOSCA шаблону;
- может настроить создаваемое окружение вручную или автоматически;
- может управлять жизненным циклом окружения (развернуть, остановить, удалить);
- может получить информацию, необходимую для доступа к окружению (пароли, ключи, конфигурационные файлы);
- может отслеживать состояние полученного окружения;
- может отслеживать состояние каждого узла в окружении;
- может обновлять конфигурацию узла в развёрнутом окружении;
- Оператор:
- может добавлять, обновлять, удалять артефакты для управления жизненным циклом ресурсов;
- может добавлять, обновлять, удалять TOSCA шаблоны;
- может валидировать создаваемые TOSCA описания;
- Администратор:
- может отслеживать состояние платформы;
Далее следует разделить создаваемую систему на функциональные компоненты. Это позволит предусмотреть возможность горизонтального масштабирования в связи с возрастанием нагрузки на конкретную функциональность независимо от других компонентов.
Операционная модель TOSCA вводит две абстракции: Resolver и Orchestrator. Эти модели и их функции, описанные в стандарте, составляют хороший фундамент для описания будущей архитектуры системы, однако в представленной модели не хватает системы хранения данных. Система, хранящая TOSCA шаблоны и представления в дальнейшем будет называться Repository.
Полученные знания позволяют получить высокоуровневую модель архитектуры:
flowchart TD
Resolver
Orchestrator
Repository
st(Service Template)
im(Instance Model)
srv(External environments)
st-->|processed by|Resolver
Resolver --produced by--> im
Orchestrator --updates--> im
st --stored in--> Repository
im --stored in--> Repository
Orchestrator --updates--> srv
Далее будут описаны функциональные требования к каждому компоненту.
Сервис Repository
Главной задачей, решаемой репозиторием, является хранение всех TOSCA описаний. Так как модель представления так же хранится в модели TOSCA, описываемый сервис подходит и для хранения этих моделей. Помимо хранения, репозиторий должен обеспечивать валидность хранимых в нём данных. Это достижимо через интеграцию с одной из систем анализа TOSCA, рассмотренных в главе 3.
Так как задачи валидации и нормализации сопряжены между собой, имеет смысл делегировать задачу нормализации этому сервису. К тому же, репозиторий является источником знаний для остальных подсистем. Это позволит выполнять нормализацию один раз при загрузке данных в систему хранения.
Отдельно стоит выделить задачу хранения артефактов. Так как к загружаемому шаблону могут быть привязаны артефакты, их обработка должна выполняться репозиторием, однако хранение необходимо вынести в отдельную подсистему, чтобы не препятствовать горизонтальной масштабируемости системы.
Таким образом, основными функциями подсистемы являются:
- Валидация ненормализованного шаблон, возвращающая список отклонений от спецификации
- Нормализация шаблона
- Добавление / обновление / удаление / чтение нормализованного шаблона
- Добавление / обновление / удаление / чтение артефакта, связанного с шаблоном
Сервис Resolver
Основная задача Resolver — композиция шаблонов и подстановка значений, введённых пользователем, для создания модели представления.
Так как модель представления описывается моделью TOSCA, необходимо разработать алгоритм, позволяющий по набору шаблонов и конфигурации, определяемой моделью ввода пользователя, получить новое нормализованное представление, которое может быть сохранено в сервисе Repository.
Так как детали реализации композиции шаблонов не описаны в стандарте TOSCA, нужно выработать набор правил композиции, следующих из спецификации substitution mapping. Высокоуровнево должны быть выполнены следующие операции:
- properties подменяемого узла должны отобразиться на inputs подставляемого шаблона
- attributes подменяемого узла должны отобразиться на attributes узлов внутри подставляемого шаблона
- capabilities подменяемого узла должны отобразиться на capabilities узлов внутри подставляемого шаблона
- requirements подменяемого узла должны отобразиться на requirements узлов внутри подставляемого шаблона.
Далее будем называть шаблон, содержащий подменяемый узел верхним, а подменяющий шаблон — нижним. Необходимо детализировать правила отображения и разрешения конфликтов между отображаемыми значениями.
Для упрощения композиции шаблонов необходимо предусмотреть API вызов, предоставляющий пользователю набор конфигурируемых параметров и доступные опции подстановки.
Основными функциями Resolver являются:
- Составление по шаблону формы с требуемыми для настройки параметрами
- Обработка заполненной пользователем формы: подстановка входных параметров в секцию inputs шаблона и композиция нескольких шаблонов в модель представления
Сервис Orchestrator
Orchestrator является связующим звеном между моделью представления и развёрнутым окружением. Основная его задача — выполнение операций над развёрнутым окружением и обновление атрибутов узлов топологии в соответствии с изменениями.
В оркестраторе необходимо реализовать изменение состояния узлов, влекущее последовательный вызов операций на этих узлах в порядке зависимостей. Так как топология TOSCA представляет собой ацикличный направленный граф, его можно упорядочить топологически и выполнять независимые операции параллельно.
Для выполнения операций сервису требуется функциональность для исполнения артефактов, привязанных к узлам. Тем не менее, вся логика кроме запуска артефакта с нужными параметрами и обработки возвращаемых значений описывается моделью TOSCA и не привязана к конкретной среде исполнения артефактов. Поэтому необходимо выделить дополнительную подсистему Runner, отвечающую за исполнение артефактов в определённой среде исполнения.
Такая декомпозиция позволяет расширять создававаемую систему оркестрации за счёт добавления новых сред исполнения, не изменяя при этом логику внутри сервиса Orchestrator. Основной функцией подсистемы Runner является исполнение артефактов определённых типов с переданными от Orchestrator значениями и последующий возврат выходов исполнения, подставляемых в outputs операции. Дополнительно необходимо предусмотреть интерфейс для логирования исполнения и сохранения логов в отдельной подсистеме.
Дополнительно следует предусмотреть механизм управления артефактами: содержащиеся в сервисе Repository артефакты и их зависимости необходимо поместить в среду исполнения так, чтобы они были изолированы от других исполняющихся в данный момент времени задач.
Основные функции системы оркестрации:
- Изменение состояний узлов топологии
- Осуществление мониторинга и автоматическое обновление состояния модели представление
Использование инструментов, разрабатываемых ИСП РАН
ИСП РАН поддерживает сервисы, выполняющие часть функциональных требований создаваемой системы. Такими сервисами являются: Clouni, Michman, Cotea.
Cotea
Сервис Cotea является полнофункциональной реализацией подсистемы Runner. Наличие GRPC интерфейса позволяет выполнять задачи Ansible удалённо с возможностью восстановления после отказов. Однако, для выполнения артефактов, отличающихся от Ansible необходимо предусмотреть использование альтернативных сред исполнения или абстракций над сервисом Cotea.
Дополнительно следует разработать механизм передачи в Cotea артефактов и изоляции исполнений, так как внутри сервиса эта функциональность не реализована.
Clouni
Сервис Clouni реализует собственный алгоритм спецификации шаблона под определённого облачного провайдера. Несмотря на схожесть с механизмом substitution mapping, этот механизм слишком специфичен и заточен под среду исполнения Ansible. Тем не менее, в Clouni реализована логика обхода графа зависимостей узлов в топологическом порядке с выполнением операций с помощью Cotea. Описанную логику можно перенести в создаваемую систему оркестрации почти без изменений, обобщив до необходимого уровня абстракции.
Michman
К сожалению, модель Michman сильно отличается от модели TOSCA, что не позволяет легко адаптировать внутренние компоненты этой системы под функции создаваемой системы оркестрации. Несмотря на то, что Michman обладает собственной подсистемой для запуска Ansible, похожая подсистема в Clouni, использующая Cotea, обладает большей функциональностью и переносима с меньшими затратами.
Тем не менее, Michman поставляется с большой коллекцией конфигураций сервисов и связанных с ними Ansible ролей, которые могут послужить реализациями операций соответствующих описаний на языке TOSCA. Перенос конфигураций сервисов Michman на уровень абстракции TOSCA является отдельной масштабной задачей, выходящей за рамки данной работы.
Описание Kubernetes с помощью OASIS TOSCA
Тестирование создаваемой системы — обширная задача. В рамках работы мы ограничиваемся валидацией системы с помощью набора TOSCA описаний для сервиса Kubernetes, предоставляемого по запросу. Ранее было заключено, что Kubernetes является хорошим примером платформы, описав которую, можно проработать ограничения стандарта TOSCA и требования к системе.
Система оркестрации должна иметь возможность:
- конфигурировать параметры кластера Kubernetes: ресурсы, выделяемые под узлы,
- предоставлять возможность выбора конечной точки развёртывания, в том числе размещения узлов одного кластера в разных облачных окружениях
- воспроизводимо разворачивать кластер Kubernetes
Чтобы описать топологию кластера Kubernetes с помощью OASIS TOSCA, необходимо следующее:
- Описать требования и зависимости для каждого узла в кластере Kubernetes с помощью TOSCA Node Types.
- Описать развертывание и настройку компонентов Kubernetes с помощью TOSCA операций и параметров.
- Использовать TOSCA шаблоны для создания обобщённого описания топологии кластера.
Композиция шаблонов
Вся топология Kubernetes могла бы быть описана в одном TOSCA шаблоне. Однако для каждой конфигурации кластера пришлось бы создавать новый шаблон.
Для решения этой проблемы необходимо использовать substitution mapping для последующей композиции шаблонов. Большинство реализаций Kubernetes отличаются:
- Выбором конечных точек развёртывания (компоненты Kubernetes можно разворачивать как в виде контейнеров в различных контейнерных средах, так и в виде сервисов непосредственно на виртуальных машинах; более того, можно разворачивать Kubernetes внутри Kubernetes)
- Выбором среды исполнения контейнеров для Kubelet
- Выбором конфигурации сети в кластере
- Выбором системы хранения
Необходимо обобщить каждый из выборов в виде описания абстрактного типа, вместо которого будет подставляться конкретная реализация, выбранная пользователем.
Стоит отметить, что выбор инструмента автоматизации, реализующего управление жизненным циклом узла тоже является конфигурируемым местом. Для этого необходимо воспользоваться substitution mapping и подставлять вместо абстрактного (т.е. не имеющего описанных интерфейсов и операций), но полностью сконфигурированного узла шаблон, реализующий развёртывание этого узла с помощью конкретного набора артефактов.
Реализация развёртывания
Для того, чтобы описанная на языке TOSCA топология вступила в свой жизненный цикл, необходимо разработать набор артефактов TOSCA, способных обеспечить развёртывание атомарных компонентов кластера.
5. Описание практической части
Если в рамках работы писался какой-то код, здесь должно быть его описание: выбранный язык и библиотеки и мотивы выбора, архитектура, схема функционирования, теоретическая сложность алгоритма, характеристики функционирования (скорость/память).
В данной главе представлены описание реализации компонентов архитектуры и оценка созданной системы через развёртывание конфигурируемых кластеров Kubernetes.
Модель данных Puccini
Для реализации подсистемы синтаксического разбора решено создать обёртку над программой Puccini. Так как Puccini наиболее широко поддерживает стандарт TOSCA, обладает широкими возможностями валидации и легко встраивается в системы, он использовался для валидации и нормализации шаблонов.
Так как модель данных, возвращаемых Puccini, отличается от модели TOSCA, хоть и изоморфна ей, необходимо было решить, приводить модель Puccini обратно к модели TOSCA или пользоваться расширенной моделью Puccini.
Использование модели Puccini имеет следующие особенности:
- Нормализованное представление в этой модели позволяет описывать все версии стандарта TOSCA, различия в которых обрабатываются Puccini;
- Модель изоморфна TOSCA с некоторыми расширениями, что позволяет привести её в исходный шаблон на языке TOSCA с незначительными отклонениями, обусловленными наличием кратких и расширенных нотаций;
Формат Clout, хоть и является более стандартизованным, но усложняет работу с моделью, поэтому решено было воспрользоваться моделью нормализованного представления, производимого командой puccini-tosca parse.
Puccini предоставляет Python библиотеку, являющуюся обёрткой над скомпилированной из языка Go библиотекой, позволяющую программным образом приводить TOSCA файлы к формату Clout, не порождая дополнительных системных процессов. К сожалению, интерфейса, дублирующего команду puccini-tosca parse в библиотеке нет, поэтому была реализована отдельная библиотека на языке Python, реализующая класс PucciniWrapper, позволяющий приводить шаблоны на языке TOSCA к нормализованному представлению.
Вместе с этим в библиотеке реализована модель данных, описыващая модель Puccini, с помощью библиотеки Pydantic. Валидация моделей Pydantic позволяет удостовериться в том, что Puccini возвращает данные в описанной модели и не нарушает контракт. Такие проверки полезны в том числе при дальнейшем обновлении используемой версии Puccini.
Библиотека для работы с графом TOSCA
Для выполнения операций над графом TOSCA разработана библиотека tosca, инкапсулирующая в себе всю TOSCA-специфичную логику, не зависящую от разрабатываемого инструмента оркестрации.
Главной зависимостью является обёртка над Puccini. Нормализованная модель упрощает операции c графом TOSCA, такие как:
- присвоение значений,
- вычисление значений, хранящихся в properties и attributes через вычисление TOSCA функций,
- наполнение графа новыми узлами, разрешение неявных предположений в модели, оставленных системе оркестрации для автоматической специализации,
- выполнение операции substitution mapping.
Для удобства работы с графом модель Puccini расширена дополнительными полями. Так как при обновлении модель десериализуется и хранится в оперативной памяти, ссылки, обозначаемые в сериализованном представлении (TOSCA функции get_property и get_attribute, а также отображения outputs), можно десериализовать в виде ссылок на объекты Python. Для этого, однако, требуется обход графа, так как сериализованные ссылки заданы путями.
Так как обход модели является распространённой задачей, создан обобщённый класс Modifier, позволяющий совершить обход модели от корня до проставленных в атрибуты и параметры значений, включая в том числе вложенные в них значения.
Modifier обладает методами update_xxx, где под xxx обозначается вид сущности в модели TOSCA, например capability или value. При вызове метода update_service_template рекурсивно обойдёт все вложенные объекты, вызывая соответствующие методы. Для выполнения специальной логики последующие модификаторы модели отнаследованы от класса Modifier, а логика методов, соответствующих обновлению необходимых объектов, переопределена с помощью перегрузки.
Для задачи десериализации ссылок реализовано два класса: Normalizer и Resolver. Первый класс призван выполнять служебную работу по проставлению обратных ссылок на родительские объекты: например, на этом этапе обработки шаблона в capability сохраняется ссылка на node, который его содержит. Resolver же находит объекты по путям к ним и проставляет явные ссылки.
Дополнительно реализован класс Coercer, позволяющий вычислить функции TOSCA, подставляя вместо них значения. Это нужно, чтобы можно было по хранимой модели отобразить её реальное состояние так, что в каждом атрибуте содержится истинное значение. Также это необходимо для подстановки значений в операции: как правило, входные параметры операции ссылаются на атрибуты узлов, чтобы отразить текущее состояние модели.
Для передачи значений в операции и впоследствии в исполняемые артефакты необходимо предусмотреть контракт. Простые типы данных поддерживаются как в модели TOSCA, так и в большинстве сред исполнения артефактов: Ansible может работать со значениями типа string, integer, boolean и так далее. Сложности начинаются, когда необходимо передать артефакту сложные структуры данных или данные, специфичные для TOSCA, например, тип данных scalar-unit, описывающий значение, обладающее размерностью (например, 42 килобайта). Такие случаи должны обрабатываться отдельно, для этого создан класс Simplifier, приводящий значения атрибутов к модели, передаваемой операциям.
Ниже приведена схема всех реализованных классов для работы с моделью:
flowchart TD
Normalizer --> Modifier
Resolver --> Modifier
Coercer --> Modifier
Simplifier --> Modifier
Substitutor --> Modifier
Незатронутым остался класс Substitutor, которому посвящён следующий раздел.
Substitution Mapping
Стандарт не описывает механизм построения связей между моделями представления, полученными из шаблонов. Одним из вариантов является хранение моделей отдельно друг от друга и поддержание ссылок от узлов на соответствующие подстановки в системе хранения или метаданных модели, что сохраняет иерархию подстановок и оставляет возможность смены подстановки в уже функционирующей модели. Недостатками такого подхода являются:
- расширение стандарта TOSCA и делегация дополнительной логики в систему хранения, что усложняет дальнейшую интеграцию с другими TOSCA-системами;
- необходимость производить композицию каждый раз при десериализации: так как модель представления часто обновляется, нужно запрашивать все зависимые модели в композиции для вычисления актуального состояния;
Другим подходом является композиция шаблонов на месте, в результате которой получается новый, специализированный шаблон. Такой механизм можно сравнить с шаблонной подстановкой в шаблонизаторе jinja2. Это не позволяет явно хранить иерархию подстановок, так как после композиции все узлы будут содержаться на одном уровне, в полученном совмещённом шаблоне. Однако, это даёт следующие преимущества:
- уменьшение количества запросов к системе хранения, так как все зависимые модели будут скомпонованы в одну;
- уменьшение сложности и объёма кода, связанного с хранением и обработкой ссылок на зависимые модели, что может упростить разработку и снизить вероятность ошибок. В рамках разрабатываемой системы выбран второй подход.
При реализации второго подхода возникает следующая проблема: при подстановке абстрактный узел заменяется набором узлов из нижнего шаблона, из-за чего ссылки на исходный узел становятся невалидными. Необходимо обновить пути в сериализованном представлении так, чтобы они ссылались на новые локации объектов, от которых они зависят. Для этого в расширенной модели объектов, у которых могут быть зависящие, было добавлено поле listeners, хранящее ссылки на зависящие объекты. Примером зависящих объектов являются функции, которые зависят от других значений, а также requirements, которые ссылаются на определённые capabilities. Для обновления путей объектам функций и requirements добавлены методы .set_target(target), позволяющие уведомить их о перемещении зависимого объекта. Такой подход позволяет поддерживать все пути корректными сразу после перемещения зависимостей.
==тут листинг set_target==
Другой проблемой является отображение properties узла на inputs. Внутри подменяемого узла может содержаться как простое значение, так и некоторая композиция функций, которые в том числе могут ссылаться на другие значения. Поэтому нельзя переносить все ссылки с отображаемого значения на input из нижнего шаблона, так как в inputs могут содержаться только примитивные значения. Переносить ссылки на атрибуты, получающие значение input через get_input в нижнем шаблоне, также не представляется возможным, так как нижний шаблон может не содержать узлов, на которые можно сослаться: например, все get_input могут являться аргументами функции concat, лишая нас возможности получить путь к ним. По этой причине решено выполнять частичное вычисление функции в таких ситуациях: значение из property явно копируется на место всех ссылающихся на него get_property, а также на место всех get_input, ссылающихся на input, куда отображается рассматриваемое значение.
==картинка==
Также была решена проблема разрешения конфликтов между значениями. Примером такого конфликта является неоднозначность выбора значения атрибута, когда тот выставлен как в верхнем шаблоне, так и в нижнем. В рамках работы зафиксировано правило: верхнее значение имеет больший приоритет, чем нижнее. Это означает, что нижнее значение остаётся выставленным только при отсутствии верхнего значения.
Все вышеперечисленные технические решения позволили зафиксировать алгоритм композиции шаблонов, реализованный в классе Substitutor.
==тут листинг функции маппинга==
Архитектура системы
Разделение системы на подсистемы позволяет реализовать отдельные компоненты в виде контейнеризированных микросервисов, которые можно развернуть в среде Docker или Kubernetes.
Компоненты системы разрабатывались в монорепозитории на языке Python. Для контроля зависимостей использовался пакетный менеджер Poetry. Такой подход упростил контроль зависимостей, позволяя при этом поддерживать каждую подсистему изолированно от других.
Подсистемы Repository, Resolver, Orchestrator реализованы в виде REST API сервисов с чётко разделёнными ответственностями согласно функциональным требованиям, описанным в главе 4. В качестве фреймворка для реализации REST API выбрана библиотека FastAPI в связке с библиотекой Pydantic для описания моделей данных. Выбор библиотек обусловлен возможностью автоматической генерации документации о API по спецификации OpenAPI, а также возможностью автоматической валидации данных, описанных моделями Pydantic. Это существенно упрощает разработку интерфейсов и интеграцию систем.
==тут кусок документации==
Сервис Resolver
Реализация
==описать тут модель данных UserWish==
REST API сервиса Resolver реализует следующие методы:
/configs- путь, по которому можно получить заполняемую пользователем формуGET /configsGET /configs/:template_id
/instanceModels- путь, по которому можно создать модель представления, передав заполненную пользователем формуPOST /instanceModels
Сервис Repository
REST API сервиса Repository реализует следующие методы:
/templates- путь, по которому можно выполнить CRUD операции с шаблонами TOSCAGET /templatesPOST /templatesGET /templates/:idPUT /templates/:idDELETE /templates/:id
/instances- путь, по которому можно выполнить CRUD операции с моделями представления TOSCAGET /instancesPOST /instancesGET /instances/:idPUT /instances/:idDELETE /instances/:id
/substitutions- путь, по которому можно узнать id шаблонов, подходящих в качестве подстановки для определённого типаGET /substitutions/:id
Для задачи хранения идентификаторов в метаданные модели шаблона был добавлен ключ michman_template_id, а в метаданные модели представления были добавлены ключи michman_instance_id, michman_instance_name. Второй ключ нужен для хранения человекочитаемого идентификатора модели представления, упрощающего идентификацию созданных моделей пользователем.
Реализация Repository выходит за рамки данной работы
Сервис Orchestrator
REST API сервиса Orchestrator реализует метод POST /instanceModels/:id/state пользуясь которым, можно запустить изменение состояния модели. При получении запроса оркестратор запускает параллельный обход узлов модели в топологическом порядке, запуская независимые операции параллельно.
На данный момент поддерживается исполнение только набора задач Ansible, а также Ansible ролей. Использование GRPC Cotea в качестве среды исполнения позволяет исполнять их контролируемо, отказоустойчиво и изолированно от самой системы оркестрации.
Pulp
В качестве подсистемы хранения артефактов взят сервис Pulp. Он позволяет загружать файлы через REST API и затем запрашивать их по определённому адресу. Выбор данного сервиса обусловлен наличием у Pulp docker сборки, позволяющей легко встроить его в разрабатываемую платформу. Дополнительным преимуществом является большое количество расширений, в том числе расширение Ansible Galaxy, позволяющее эмулировать официальный репозиторий Galaxy, загружая туда Ansible коллекции и роли. В рамках данной работы использовалась базовая функциональность загрузки файлов.
Для взаимодействия с Pulp была реализована Python библиотека, реализующая класс PulpClient с методом upload_artifact. При вызове метода клиент загружает переданный файл в хранилище Pulp и возвращает ссылку, по которой можно его получить.
Так как роли Ansible являются связанным набором файлов, хранимых в директории, дополнительно предусмотрена возможность сжатия загружаемых директорий в ZIP архив с помощью модуля shutil. Это позволяет работать с Ansible ролями как с неделимыми сущностями на стороне системы оркестрации.
Хранение секретов
==пока с секретами мы никак не работаем, но про это точно надо что-то сказать==
Итоговая модель
В результате была получена следующая архитектура системы:
Создание профиля Kubernetes
Для проверки возможностей системы оркестрации был создан набор TOSCA профилей, содержащий в себе типы, позволяющие описывать различные топологии Kubernetes.
Чтобы не опираться в создании профиля на создаваемую систему оркестрации, а систему оркестрации не тестировать на созданном профиле, было решено воспользоваться сторонними инструментами, поддерживающие подмножество TOSCA, наиболее близкое к стандарту TOSCA simple profile 1.3. Для валидации шаблонов и проверки возможности развёртывания был выбран легковесный оркестратор xOpera. Так как xOpera не поддерживает substitution mapping, описание топологии Kubernetes содержалось в единственном шаблоне. Для реализации выбран инструмент Ansible, так как это единственная поддерживаемая xOpera среда исполнения.
OpenStack
==описать профиль OpenStack==
PKI
В процессе создания кластера Kubernetes выпускаются сертификаты, используемые его компонентами. В том числе, существуют сертификаты, используемые каждым компонентом кластера: например, корневой CA сертификат.
Так как стандарт TOSCA не поддерживает динамически возникающие артефакты и передачу таких артефактов между узлами, был разработан профиль PKI, инкапсулирующий в себе работу с выпуском сертификатов. Для этого создано два типа kubetos.nodes.Certificate и kubetos.nodes.CertificateAuthority, которые содержат выпущенные сертификаты и соответствующие им ключи в строковом формате в атрибутах capabilities cert и ca соответственно. При этом, Certificate имеет в качестве зависимости CertificateAuthority, выпускающий данный сертификат. Вместе с типами создано два шаблона, реализующих интерфейсы для выпуска сертификатов каждого типа. Эти шаблоны могут быть подставлены на место абстрактных типов для автоматического выпуска сертификатов. В то же время, пользователь имеет возможность подставить собственные сертификаты вместо заданных.
Для выпуска сертификатов реализованы Ansible сценарии, использующие встроенные модули для работы с сертификатами.
CNI
==описать CNI==
CRI
==описать CRI==
Etcd
==описать etcd==
Kubernetes
Для реализации развёртывания компонентов Kubernetes мог быть взят инструмент Kubeadm, однако есть несколько причин, по которым этот инструмент не подходит для управления жизненным циклом отдельных компонентов:
- Kubeadm является отдельным бинарным файлом, добавление которого повлекло бы добавление лишней зависимости у каждого узла
- Kubeadm не даёт полного контроля над создаваемыми компонентами, скрывает абстракции и добавляет лишний слой управления
По этим причинам решено отказаться от использования каких либо инструментов, упрощающих развёртывание Kubernetes, в пользу полностью ручного развёртывания.
Cоздан набор сценариев развёртывания, основанный на кодовой базе инструмента Kubespray. Исходные роли Kubespray тесно связаны и не могут быть использованы по отдельности. В рамках работы была проведена декомпозиция ролей, выделены такие роли как:
cri-o- роль, совершающая установку и настройку сервиса CRI-Orunc- производит настройку runckata- производит настройку kata
cni- роль, совершающая установку и настройку CNI плагиновkubelet- роль, устанавливающая сервис kubeletetcd- роль для развёртывания etcd.
Kubetos
На базе Opera создан набор профилей Kubetos версии 1.0 (==ссылка==). Благодаря возможности параллельного развёртывания узлов, оркестратор Opera способен развернуть топологию Kubernetes на двух вычислительных узлах за 8 минут 30 секунд, что задаёт базовую планку для создаваемой системы оркестрации.
==Сказать про то, что получился гига-шаблон на 100500 строк, для конфигурации которого недостаточно заполнения inputs: в шаблоне уже проведена специализация под облачного провайдера OpenStack, выбраны конкретные реализации систем контейнеризации и сетевых интерфейсов==
Декомпозиция шаблона
Ограниченность поддержки стандарта TOSCA в оркестраторе Opera не позволяет расширять профили дальше, поэтому Puccini был выбран новым инструментом синтаксического анализа и валидации шаблонов.
Благодаря TOSCA substitution mapping, шаблон топологии Kubernetes разделён на несколько шаблонов, что позволило декомпозировать описание на слои: от более абстрактного описания к более конкретному. Такая декомпозиция позволяет выбирать параметры кластера в момент создания представления топологии по шаблону.
Шаблон самого высокого уровня предназначен для конфигурации числа узлов и общих параметров кластера. Такую конфигурацию предоставляет каждый инструмент развёртывания Kubernetes.
Более страшная картинка, но сгенерирована создаваемым прототипом по внутреннему представлению топологии:

Такое описание не фиксирует конкретную реализацию, вместо абстрактных вершин могут быть подставлены более конкретизированные шаблоны. Этот выбор может быть сделан как пользователем в момент создания топологии, так и автоматически в случае, если пользователю не важна конкретная реализация.
Так как топология плоскости управления тоже стандартна, её можно вынести в отдельный слой абстракции:
Стоит отметить, что выделение отдельной сущности worker позволило не описывать внутреннее устройство дважды: в верхнеуровневом описании топологии Kubernetes и в более низкоуровневом описании устройства плоскости описания.
Устройство worker узла вынесено в отдельный шаблон топологии:
Здесь можно спуститься на уровень абстракции ниже и описать реализацию интерфейса CRI с помощью конкретного контейнерного движка: cri-o, containerd, docker (cri-dockerd)
Оценка развёртывания
Для оценки созданного решения, разработанная платформа была поднята с помощью Docker Compose на локальной машине. Профили Kubetos были загружены в платформу с помощью подготовительного скрипта, который также осуществил загрузку артефактов исполнения в сервис Pulp.
curl localhost:10002/api/v1/configs
curl localhost:10002/api/v1/config/:id
==Тут пример заполненной UserWish формочки, пока пример из ray-mlflow==
{
"instance_name": "shishqa-test",
"template_id": "23b59d7644404983a87859763700288e",
"substitutions": {
"ray": {
"template_id": "ca0c41ead14045d1970aab2ed90d5815",
"substitutions": {
"ray-host": {
"template_id": "26338aaf3fc04a4bb6b1e20c5053dfa9",
"inputs": {
"key_name": {
"$meta": {
"type": "string"
},
"$primitive": "shishqa-toadster"
},
"floating_ip_pool": {
"$meta": {
"type": "string"
},
"$primitive": "ispras"
}
}
}
}
},
"object-store": {
"template_id": "a52ca3c336bb407f8fdc95d7716eda87",
"substitutions": {
"minio-host": {
"template_id": "26338aaf3fc04a4bb6b1e20c5053dfa9",
"inputs": {
"key_name": {
"$meta": {
"type": "string"
},
"$primitive": "shishqa-toadster"
},
"floating_ip_pool": {
"$meta": {
"type": "string"
},
"$primitive": "ispras"
}
}
}
}
},
"back-store": {
"template_id": "47bf77f7245d4cc8ab65debfc9afdc7e",
"substitutions": {
"pg-host": {
"template_id": "26338aaf3fc04a4bb6b1e20c5053dfa9",
"inputs": {
"key_name": {
"$meta": {
"type": "string"
},
"$primitive": "shishqa-toadster"
},
"floating_ip_pool": {
"$meta": {
"type": "string"
},
"$primitive": "ispras"
}
}
}
}
},
"mlflow": {
"template_id": "c5170d68f9614cf189bb5e4a776df429",
"substitutions": {
"mlflow-host": {
"template_id": "26338aaf3fc04a4bb6b1e20c5053dfa9",
"inputs": {
"key_name": {
"$meta": {
"type": "string"
},
"$primitive": "shishqa-toadster"
},
"floating_ip_pool": {
"$meta": {
"type": "string"
},
"$primitive": "ispras"
}
}
}
}
}
}
}
curl -X POST -d '@example.json' localhost:10002/api/v1/instanceModels
==Тут про время развёртывания и процесс создания инстанса по шаблону==
6. Заключение
Здесь надо перечислить все результаты, полученные в ходе работы. Из текста должно быть понятно, в какой мере решена поставленная задача.
- Исследование
- Изучены возможности и текущие ограничения стандарта TOSCA;
- Проведен сравнительный анализ существующих систем окрестрации, поддерживающих TOSCA;
- Изучены архитектуры существующих дистрибутивов Kubernetes, выделить общие для всех решений возможности конфигурации платформы.
- Практика
- Разработан набор определений на языке TOSCA для Kubernetes, смоделировать с помощью полученных определений топологию Kubernetes;
- Разработана архитектура системы оркестрации, описаны требования к каждому компоненту;
- Релизован REST API микросервис, способный осуществлять композицию шаблонов через Substitution Mapping; Созданный микросервис успешно интегрирован в создаваемую систему;
- Смоделированная платформа Kubernetes успешно развёрнута с помощью созданной системы.
Список литературы
==не умею рендерить Biblatex в md 🌚==